写在前面 😶
比赛官网: 智源 - 看山杯 专家发现算法大赛2019
参赛时间: 2019.11.20-2019.12.17 其实是在CCF2019乘用车销量预测刚结束,转场到看山杯的,一个月过的好快。
比赛结果: 定榜第八名(希望能公费旅游???),在此感谢开源baseline的大佬们和我四个队友(又是做特征又是敲代码的土旺、晓燕 做模型融合的佳佳和浩波)
这次比赛算是第一个认真对待,带着脑子去联系实际思考的比赛,起初只是觉得需要有个比赛能在简历上说得过去,逼迫着打比赛,但是到后面真的能发现比赛的乐趣,
理解模型上线也确实要考虑的很多东西,这是在乘用车中没有体会到的,可能是乘用车比赛给的数据和特征都很少,所以不知道怎么去马特征特征,更没有考虑到优化问题。
这次比赛,印象最深的就是第一次在baseline上加特征(提取用户在邀请日之前所有历史回答问题绑定的话题),一条条apply,没有groupby,没有agg,自以为十几个小时能跑完,
晚上就挂在服务器上跑,第二天早上来看还没完(原谅我当时还没习惯用tqdm),心态崩了,只好狠心停掉,用tqdm看了一下竟然要跑六天….看到这里你肯定会很无语,
没错我也很无语,经过优化后只要几个小时,我都感动哭了…
言归正传,来说一下比赛经历,怕自己给忘了。
数据问题 😥
登录官网发现有近10G,以为只有cv类比赛才会有这么大的数据hh,顿时不知道从哪里下手,花了一天来熟悉原始数据(所有数据均已脱敏处理)。
存在难点:①数据量大且稀疏 ②时间跨度不一,容易特征穿越
时间轴
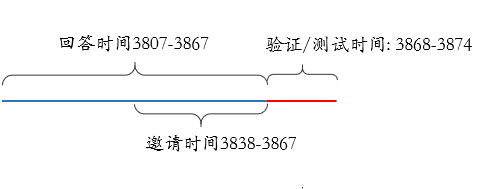
基本信息
| 数据 | 说明 | size(条) |
|---|---|---|
| single_word_vectors | 64维单字编码(embedding) | 2w |
| word_vectors | 64维词编码(embedding) | 176w |
| topic_vectors | 64维话题ID编码(embedding) | 10w |
| question_info | 涉及的所有问题相关信息(包括问题ID、创建时间、标题与描述的字词编码、问题绑定的话题ID) | 1829900 |
| answer_info | 被邀请用户近两个月的回答信息(包括用户ID、回答ID、问题ID、创建时间、回答内容、回答特征) | 4513735 |
| member_info | 涉及的所有用户信息(包括用户ID、性别、关注及感兴趣话题、用户分类特征) | 1931654 |
| invite_info | 邀请数据(训练集),包括(邀请的问题ID、用户ID、邀请时间、是否回答-label) | 9489162 |
| invite_info_evaluate | 邀请数据(验证集),包括(邀请的问题ID、用户ID、邀请时间、是否回答-label) | 1141683 |
验证集和测试集分布还是挺相似的,最后将验证集和测试集整合在一起,完整数据,有较大的提升:
| 类别 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| size(条) | 9489162 | 1141683 | 1141718 |
| 问题数 | 926203 | 237167 未邀请过的问题157524 两个月内没有回答的问题198937 未邀请也未回答过的问题155874 |
237312 未邀请过的问题157744 两个月内没有回答的问题199209 未邀请也未回答过的问题156065 |
| 用户数 | 1358213 | 613340 未邀请过的用户61052 两个月内没有回答的用户189292 未邀请也未回答过的用户57273 |
613733 未邀请过的用户61461 两个月内没有回答的用户189017 未邀请也未回答过的用户57580 |
数据建模
采用了两种训练集划分方式。
1.无划分式
将邀请时间作为特征,并将每条邀请信息视为单独的样本,无划分方式真的有点无脑,其实也是实践能力不行,一条路走到底,没有思考其他划分方式我太菜了…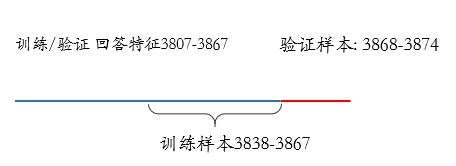 优点:
优点:
样本多,训练得到的树模型鲁棒性强。
缺点:
① 近千万的邀请数据构成近千万个样本,每个样本都需要进行特征提取,工程量大,训练时间漫长。
② 历史特征划窗在训练集前七天和验证集上无法和其他样本保持跨度一致。
③ 样本多的同时其实也带来了某些outlier。
2.有划分式
将邀请时间后七天(3861-3867)作为训练集,将
 优点:
优点:
训练集与验证集特征提取方式保持一致。
缺点:
只用七天的数据进行训练,模型学习所需要的正样本过少。
3.五折交叉
在无划分方式的基础上进行五折交叉验证,训练五个模型对结果取平均。
数据清洗
1)缺失数据:其实很多特征都有缺失值
① 比如用户性别(male female unknown),本来想根据其他用户特征用随机森林预测性别进行填充,看了看unknown数占的太多了,就放弃了,还是直接当作第三类吧…
② 比如问题绑定话题、问题描述、用户关注话题等(’-1’占位),怎么处理这些值? 用用户回答的高频话题填充用户关注话题??
③ 用户感兴趣分数inf处理
2)重复数据:通过drop_duplicates对训练集中162个重复数据去重(脏数据)。
3)无意义特征:用户侧创作关键词、注册类型、注册平台等特征人均相同,不具有区分度,需要剔除。
评价指标 🧐
使用AUC对提交数据与真实数据进行衡量评估,AUC:ROC曲线面积,可直观评价模型性能。
- ROC曲线
与PR曲线使用查准率、查全率作为纵、横轴不同,ROC曲线使用真正例率(TPR)作为纵轴,假正例率(TPR)作为横轴(至于为什么不用PR曲线,当然是因为PR曲线在正负样本不平衡时效果较差,检索用PR分类识别用ROC)。
与PR图类似,若一个学习器的ROC曲线被另一个学习器曲线覆盖,则可断言后者性能优于前者;若两个学习器ROC曲线发生交叉,则难以判断孰优孰劣,因此较为合理的是比较ROC曲线的面积,即AUC。 - AUC
AUC值是一个概率值,当随机挑选一对正负样本,当前分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,说明当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
计算步骤(假设n个样本):
① 对预测score从大到小排序,令最大的score对应的sample rank为n,次大的label对应为n-1,以此类推至1。
② 将所有正样本rank相加,减去M-1种两个正样本组合的情况,得到n个样本中正类样本预测label大于负类样本的数目,然后除M*N。
计算公式: (假设M为正样本数,N为负样本数,$rank_{i}$为第i个正样本所在位置)
$$AUC=\frac{\sum_{iepositiveClass}rank_{i}-\frac{M(1+M)}{2}}{M \times N}$$
模型选择 😟
Xgb or Lgb
从理论上讲Lgb比Xgb更合适。
① Lgb能直接处理categorical feature,而Xgb需要对进行one-hot/dummy处理,看山杯用户的多分类特征有上千个值,节点分裂时采用贪心算法,计算量非常大,且可能会出现按ID分裂的子树,容易过拟合。
② 由于比赛数据特征高维稀疏,比如回答特征中回答是否被标为优秀回答、回答收到感谢数、回答收到的没有帮助数、回答点赞数取赞数等等存在大量互斥特征,Lgb提出EFB方法将互斥特征bundle为单一特征,减少分裂时的特征数。
③ 数据集共包含千万条邀请信息,在这些邀请中,很多问题都没有人回答过,很多用户都在潜水,因此存在正负样本失衡问题,Lgb提出GOSS方法对样本采样,加速模型训练。
更重要的是由于参赛较晚,已经有大佬开源了现成的Lgb Baseline,所以直接就借鉴了基层代码。
实践出真知,之后也验证了一下两个模型,在训练数据、迭代次数、学习率一致,其他模型参数差不多的情况下,Xgb低了大概九个千分点(lgb线上0.832,Xgb线上0.823),
至于速度,Xgb设置了GPU参数,但是LGB如果设置在GPU上运行时max_bin参数不能超过63(这个很奇怪,就一直报错),然后就没用GPU版本了,所以两者速度其实差不太多。
官方解释: 题外话:乘用车用Xgb跑出来的效果要比Lgb好一点(下回分解)。
题外话:乘用车用Xgb跑出来的效果要比Lgb好一点(下回分解)。
DeepFM
本次比赛数据高维稀疏且需要特征组合,因此尝试了DeepFM模型,DeepFM由FM和DNN构成,分别提取低阶和高阶特征,相比于Wide&Deep,可共享输入,进行端到端训练。
测试模型调整FC为三层(256,128,128)将精度从0.8↑0.82,可能是由于连续特征值过多,压缩到embedding效果不太好。
特征工程 😞
统计特征
用户特征
① 用户关注话题数、感兴趣话题数;
② 对类别特征进行count encoding(包括memberID、questionID、用户多分类特征)并归一化,可能造成特征不同,编码相同的情况。可以看看类别特征常用编码方法,其实有八种来着;
③ 用户的邀请回答率;
- 训练集无划分方式中,由于将时间视为特征,考虑到邀请回答率是用户长期累积行为,所以算邀请日前总回答率,而且验证集七天与训练集区间不一致, 验证集后七天回答率取值训练集最后一天是一样的(逐天预测会导致误差传播,不可取)。在有划分方式中训练集和测试集的计算方式是一样的。
- 一个严重问题:用户回答在邀请之后,算不算特征穿越,如果模型要上线,这个特征每天都在变化,就很乱??
问题特征
① 问题标题及描述的字数和词数,问题绑定话题数;
② 问题创建至被邀请的时间间隔;
③ 问题在邀请时刻前1、2、4、8、16、24、32小时的邀请数(回答数),观察发现,邀请时刻前一段时间的问题邀请数与该问题的用户回答数呈正相关;
④ 构建话题热榜,为邀请问题添加热度权重(类似知乎热榜,考虑到社会热点问题可能引起广泛关注);
交叉特征
① 用户关注话题和感兴趣话题与问题绑定话题的交集数,计算感兴趣分数;
② 用户在邀请日前7-前30的24天回答特征,划窗计算,主要包括;
- 问题条数、字数,话题数、点赞数等等,我人为的绑定了一下正面特征(点赞数、认为有帮助数、圆桌数等等)和负面特征(反对数、举报数等等),效果不咋地,后面看了一下论文,Lgb可以实现特征bundle,naive~;
- 另外观察发现大多用户所回答的话题与关注话题、感兴趣话题毫无交集,对回答话题进行频次统计并设置权重,方便之后与邀请问题绑定话题计算(效果不咋地,我想了一下原因:既然现在与过去无关,那未来也与现在无关);
③ 统计邀请日前七天邀请问题与用户历史回答问题的切词交集数;
④ 分层特征,话题的用户(二/多)分类特征偏好,比如男性可能比较关注体育赛事相关问题,而女性比较关注明星八卦等问题;
⑤ 后续:问题被回答的点赞、回答数统计;
文本特征
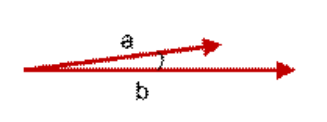
主要用的方法就是计算余弦相似度。
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。 余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似。
 ① 邀请话题与用户关注话题、感兴趣话题、历史回答话题余弦相似度,历史回答问题进行了min/mean/max统计;
① 邀请话题与用户关注话题、感兴趣话题、历史回答话题余弦相似度,历史回答问题进行了min/mean/max统计;
② 邀请问题与用户历史回答问题标题及描述的切词相似度;
模型融合 😏
其实模型融合尝试了挺多方法的,但是感觉没有规律的在试,主要用的融合模型有:无划分式+Lgb、有划分式+Lgb、无划分式+Xgb、无划分式+deepfm, 最后用上的只有前面两个,之所以能提升主要是因为数据集划分带来的差异性。
平均
算数平均:
各模型结果的均值,会使结果平滑,可能也会抵消各自的”特色“,实验效果相比几何平均低了快一个百分点。
加权平均:
$$x=\frac{x_{1} w_{1}+x_{2} w_{2}+\cdots+x_{n} w_{n}}{w_{1}+w_{2}+\cdots+w_{n}}$$
加权平均方法的权重一般从训练数据中学习得到,看山杯数据新用户、新问题较多,可能存在噪声,导致学习出来的权重并不可靠,实验效果相比于几何平均低几个千分点。
几何平均:
$$x=x_{1}^{\beta}\times x_{2}^{1-{\beta}}$$
两个模型乘积开方,几何平均得到的结果整体偏小,但是auc会比较好,最终提交采用无划分+Lgb和有划分+Lgb的几何平均。
sigmoid平均:
$$x=f\left(\frac{f^{-1}(x_{1})+f^{-1}(x_{2})+f^{-1}(x_{3})}{3}\right)$$
这里的$f^{-1}$为$f$的反函数,适合模型差异较小的时候使用。
stacking
Stacking第二层采用了LR模型,效果不如无划分+Lgb和有划分+Lgb的几何平均,分析:Stacking融合模型差异越大融合效果越好, 而我们的Lgb模型只是训练集划分方式不同,特征提取都差不多,效果不佳,而如果采用Xgb和Lgb融合,Xgb单模的精度限制了总体的精度。
总结一下 😳
历时两个月的比赛结束了,存在很多问题;
① 未考虑新用户与新问题的冷启动问题;
② 问题描述、标题等等还有太多没有挖掘的信息
③ 大数据下如何较好的平衡时间复杂度,合理利用资源;
④ 敲代码的时候多总结、条理清晰;
⑤ 不要一条路走到底,只追求特征工程,可以多思考建模方式;